CIPA Litigation Prevention Guide
Understand why CIPA lawsuits are rising and how to minimize privacy risk on your website.
Thank you!
Please check your email to view the guide.
Mitigating CIPA Litigation Risk: The Strategic Shift to Server-Side Tracking
May 26, 2026
5
mins read

California Invasion of Privacy Act (CIPA) litigation is currently the greatest privacy compliance risk for companies in the US. Law firm Constangy estimates 50,000–100,000 CIPA claims were filed between 2022 and 2025, resulting in about 7,500 settlements. Most lawsuits are kept confidential, but some of the publicized class actions have yielded large settlements, including Kaiser Permanente’s $46 million and Aspen Dental’s $19 million settlements.
The vast majority of CIPA cases target websites that share personal data with third parties without proper consent. With $5,000 in statutory damages per violation and a private right of action, even modest website traffic in California creates eight-figure theoretical exposure.
A new approach is gaining traction to reduce that exposure: moving tag managers from client-side to server-side. Instead of letting third-party pixels fire directly from the user’s browser, a server-side tag manager receives the data first, then forwards a subset of that data to advertising vendors from the company’s own server infrastructure. The recent Smith v. Rack Room Shoes decision (N.D. Cal., January 23, 2026) is likely the first time a court has publicly confirmed that using server-side tracking can lead to dismissal of CIPA wiretap claims.
Server-side tracking reduces legal exposure by physically separating the collection of personal data on the website from the sharing of that data with third parties, moving the sharing mechanism to a backend environment. Crucially, this vastly reduces the amount of visible evidence plaintiffs' attorneys can gather directly from a website's frontend to build their CIPA cases.
Server-side tracking is not a CIPA cure-all. Even though evidence is harder to gather, any public information can be used, such as case studies mentioning adtech partnerships involving data sharing. If a case gets past the pleading stage and to discovery, the defendant would then have to share logs of the backend sharing from their server-side tag manager and that data could implicate the defendant if personal data is shared with advertisers without proper consent. Additionally, server-side tracking would not protect against CIPA violations for using a session-replay tool that captures sensitive personal data.
Server-side tracking also does little to shield against enforcement for California Consumer Privacy Act (CCPA) and other US privacy laws.
Continuous privacy auditing is still needed to ensure compliance on websites (and mobile apps), and Privado AI offers the most comprehensive solutions to monitor websites and apps and flag all privacy risks in real time.
How CIPA cases are typically argued
Plaintiffs’ attorneys typically rely on two sections of the California Penal Code, all originally written to address 1967 telephone wiretapping. Server-side tracking reduces risk for both sections of CIPA.
- CIPA § 631 (Wiretapping)
- Restriction: Prohibits aiding a third party to intercept communications in transit without consent from all parties
- Argument strategy: The website operator aids third parties in intercepting the contents of user communications in real time via pixels, scripts, or real-time bidding tools
- CIPA § 638.51 (Pen Register / Trap and Trace)
- Restriction: Prohibits installing or using a "pen register" or "trap and trace device" without a court order or consent from all parties. A pen register is defined as a device or process that records or decodes "dialing, routing, addressing, or signaling information" and it does not have to occur in real time
- Argument strategy: Pixels or scripts are pen registers that capture users’ addressing information such as IP address or device ID without consent
In a small percentage of CIPA cases, plaintiffs argue that the use of website session recording tools, such as Hotjar or Fullstory, violate § 632 of CIPA. § 632 prohibits intentionally recording confidential communications without all parties’ consent. Plaintiffs typically argue that sensitive data captured by the session recording tools, such as what people type into forms, makes the communication confidential and recording unlawful.
How evidence is typically gathered for CIPA cases
Client-side tracking makes evidence gathering easy. Plaintiffs’ attorneys do not need internal access or discovery. From any browser’s Network tab, they can capture the full list of third-party scripts loaded, the exact payloads of data sent, the precise timing of each request (to demonstrate contemporaneous interception), and the behavior of tracking after opt-out. Users simply have to right-click a web page and select inspect to see this data flow activity. A complete CIPA complaint can be assembled in a few hours.
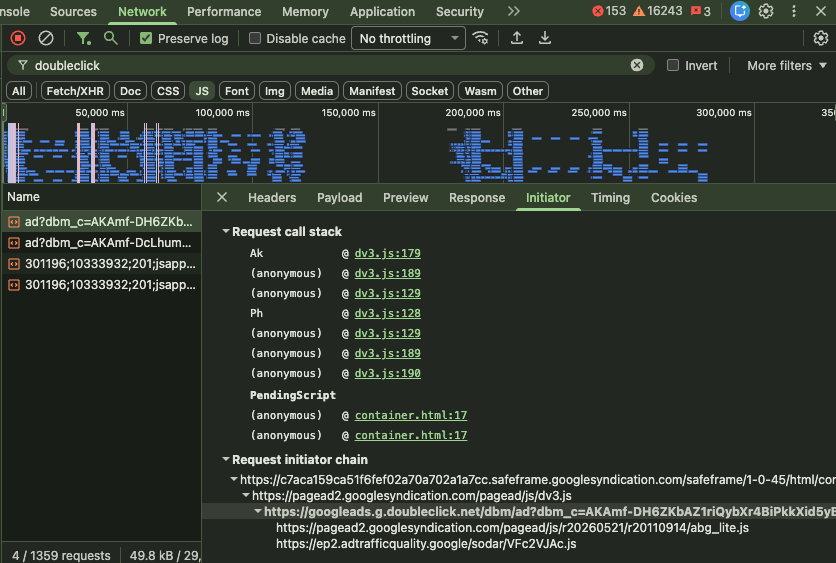
In each CIPA case, the plaintiff is typically the one who used the website and captured the data shared via screenshots of their web browser. Because it is so easy to gather this evidence, law firms and their investigators often pay people called “testers” or “cookie trolls” to test websites en masse and find opportunities to send CIPA demand letters. Law firms can quickly build a case just from the testers’ browser screenshots that show the data shared and the disclosed privacy policies.
What is server-side tracking and what the court has said about it
The typical client-side tracking setup
Nearly every website uses tools, e.g., Google Analytics, to analyze traffic and user activity, and these tools are typically implemented “client-side.” “Client-side” means the code used to run the tool is executed in the user’s browser, i.e., the client. Practically, this means the tool’s code is inserted with the rest of the web page’s code that runs when the page is loaded.
Client-side tracking refers to data collected by first or third party pixels, also known as tags, that are implemented as described above. Pixels are either implemented individually or via a tag manager. Tag managers simplify implementation and ongoing management by using one piece of code to run any pixel or tag that is set up in the tag manager. Most websites with a lot of pixels use tag managers because it enables non-technical teams to easily change pixels without changing the website’s code.
Regardless of whether pixels are implemented individually or via tag managers, their activity is still visible to the user if implemented client-side.
How server-side tracking is different
In a server-side setup, only a single first-party endpoint loads in the browser. The browser sends data to that endpoint, which runs on the company’s own server infrastructure. That server then decides which third parties receive which data and forwards filtered payloads from the server. The browser no longer communicates directly with advertising third parties — the company’s server does.
What Smith v. Rack Room Shoes established
On January 23, 2026, Judge Rita Lin issued an order in Smith v. Rack Room Shoes that is now the leading authority on server-side tracking under CIPA. The case involved both client-side and server-side tracking. The client-side CIPA wiretap claims survived. The server-side claims, based on Rack Room Shoe’s use of Zeta’s server-side code, were dismissed without leave to amend:
“Although the TAC alleges that the server-side tracker “directly forward[s]” communications and does so on an “automatic” basis, there is no information about how soon this forwarding occurs or whether it is contemporaneous with the receipt. As pled, the TAC thus fails to allege that Zeta “reads, or attempts to read, or to learn the contents or meaning” of Plaintiffs’ communications ‘in transit.’” — Smith v. Rack Room Shoes, Inc. (N.D. Cal. Jan. 23, 2026)
The court further noted that some authorities have held that automatic server-side routing occurring after a communication reaches its destination does not satisfy CIPA § 631’s "in transit" requirement at all as a matter of law. The trend is clear: server-side architectures make contemporaneous interception substantially harder to plead, and courts will not allow plaintiffs to repeatedly retry server-side theories.
How server-side tracking reduces CIPA exposure
Limited tracking evidence for plaintiffs to make a case
The entire CIPA pixel-litigation industry runs on a discovery-light investigation model: plaintiff-side investigators open a browser, fire up DevTools or a proxy like Charles, navigate the target site, and capture screenshots of outbound POSTs to facebook.com/tr/ containing the user's email hash, cart contents, search queries, etc. That packet capture becomes Exhibit A to a demand letter and survives the inevitable motion to dismiss because it's specific.
With server-side tracking, that traffic is invisible from the user's machine — it travels server-to-server between the defendant's backend and the third-party’s server. The investigator sees only an outbound request to a first-party-looking subdomain like metrics.example.com. Without the packet-level receipt, demand-letter pipelines run dry, and the cases that do get filed land at the pleading stage without the specifics needed to plausibly allege a § 631 violation.
Smith v. Rack Room Shoes illustrates this exactly: plaintiffs pleaded the Meta Pixel claim with field-by-field specificity (search queries, button names, cart contents, hashed PII) and survived multiple motions to dismiss on that theory. The parallel server-side claim against Zeta was dismissed because plaintiffs could only allege "directly forward[s]" and "automatic" forwarding — they couldn't say when the forwarding occurred or whether it was contemporaneous with receipt. The court dismissed without leave to amend. If Rack Room Shoes had implemented all pixels server-side, the plaintiffs likely wouldn’t have had enough evidence to even try to send a demand letter.
The "in transit" element of CIPA § 631 becomes structurally harder to plead
CIPA § 631 prohibits a third party from reading communications "in transit." Server-side architecture creates a doctrinal gap that's hard for plaintiffs to bridge:
- The user's browser sends data to the defendant's own server.
- The defendant — as a party to the communication — receives it under the party exception.
- The defendant's server then makes a separate, later outbound request to Meta.
- That second request isn't an "interception" of the original communication; it's a new communication originated by the defendant.
Under Torres v. Prudential Financial (N.D. Cal. Apr. 17, 2025), data that's "read" only after transmission completes doesn't satisfy the "in transit" element — even though that case involved session-replay rather than CAPI. The same logic maps onto server-side ad-tech: the data isn't read by Meta while it's traveling from the user's browser; it's read by Meta later, after the defendant has already received and processed it.
In Smith v. Rack Room Shoes, Judge Lin expressly flagged but didn't decide "the more fundamental question of whether server-side tracking technology that results in contemporaneous eavesdropping on electronic communications" violates CIPA. The defense bar reads this as an open invitation; most expect at least some courts to hold that server-side forwarding is categorically outside § 631.
The party exception gets stronger
CIPA § 631 has a long-recognized party exception: a participant in a communication can't wiretap it. Plaintiffs in pixel cases have gotten around this by arguing the third party (Meta, etc.) was simultaneously receiving its own separate communication from the user's browser, making it a third-party eavesdropper rather than a party.
Server-side tracking eliminates that argument entirely. There's no separate user-to-Meta communication — the user only ever communicates with the defendant, who then communicates separately with Meta. The defendant is unambiguously a party to the first communication, and Meta is unambiguously the intended recipient of the second. Neither is eavesdropping on the other.
This is the architectural mirror image of the holding in Cole v. Quest Diagnostics (3d Cir. Nov. 13, 2025), where the Third Circuit affirmed dismissal because the pixel provider was a direct recipient of a separate concurrent communication. Server-side tracking makes the "separate communication" structure even cleaner.
The "device or process" element of CIPA § 638.51 (pen register) gets more contestable
The plaintiffs' bar has been pivoting from § 631 to § 638.51's pen-register provisions because the latter doesn't require contemporaneous interception. But § 638.51 still requires a "device or process" that captures routing or addressing information.
Server-side architectures invite the argument that the only "device or process" operating on the user's side is the user's own browser communicating with the defendant's own server — nothing third-party-facing happens client-side. Whether that argument wins varies by court; the trend in 2025–2026 has been toward narrower pen-register readings, but it's unsettled.
Consent-related defenses get easier to establish
CIPA generally requires all-party consent. Defendants typically argue users consented through privacy policy disclosures, cookie banners, or terms of use. Server-side architecture indirectly strengthens this for two reasons:
- The defendant's privacy policy is the only relevant disclosure (there's no separate third-party direct collection to disclose), making the consent picture simpler.
- Consent management platforms can more reliably control server-side firing because the trigger is the defendant's own backend, not third-party JavaScript that may fire before consent is captured. The "pre-consent firing" problem — a major pleading theory in 2025–2026 — largely goes away.
Server-side tracking is not a privacy cure-all: What server-side tracking does NOT protect against
CCPA exposure is largely unchanged
CCPA defines "sale" and "share" based on whether personal information moves to a third party for ad-targeting purposes — it doesn't care whether the bytes traveled client-side or server-side. A server-side tag or conversion API implementation that forwards email hashes and purchase events to Meta is just as much a "share" as a client-side pixel doing the same thing. And § 1798.110 / § 1798.115 right-to-know requests are an evidence-production tool that bypasses the technical opacity entirely: a tester can submit a verifiable request and force the business to disclose its third-party recipients. If the response misrepresents the data flows, that's its own CCPA violation. So server-side is a CIPA shield much more than a CCPA shield.
No protection for CIPA § 632 claims against session replay tool usage
The Rack Room Shoes decision addressed CIPA § 631 only. CIPA § 632 exposure from session replay tools, chatbots, and form-input capture is unchanged.
Discovery, once you get there, is the same
If a case survives the pleading stage on any theory — CCPA, UCL, Wiretap Act, CDAFA, or surviving CIPA claims — server logs, CAPI configuration files, vendor contracts, and events manager records become fully discoverable. Those typically show the same data flows the plaintiff suspected. So server-side is best understood as a pleading-stage shield, not actual immunity once discovery opens.
Hybrid client-side and server-side setups still create exposure
This is a common challenge with the server-side tracking approach. In practice, very few companies run pure server-side tracking on their websites. It’s much easier for teams and vendors to implement tracking tools client-side. Vendors like Meta often recommend hybrid (pixel + conversion API) to improve ad measurement and performance. As long as any pixel fires client-side — even just PageView — plaintiffs have a foothold for that subset of events, and the client-side pixel's eventID parameter is itself a tell that matching server-side events exist.
Public-record investigation still works
Vendor case studies ("How Brand X uses Meta CAPI for a 40% lift"), job postings ("seeking engineer with Stape and server-side Google Tag Manager experience"), privacy policy disclosures, consent management platform (CMP) vendor lists, DNS / CNAME lookups on first-party subdomains, and TLS certificate transparency logs all provide circumstantial evidence of server-side architecture. The plaintiffs in Smith v. Rack Room Shoes apparently knew Zeta was involved through exactly these channels; they just couldn't get to packet-level specificity from outside.
Implementing Server-Side Tracking: Best Practices
- Use a first-party subdomain: The server-side container must be reachable at a subdomain of your primary domain (e.g., tags.example.com), not a vendor-hosted one.
- Implement tracking via server-side tag manager: Tag managers like Google Tag Manager or Tealium simplify implementation and management for web and marketing teams. See Google Tag Manager server-side documentation.
- Migrate all advertising and analytics tags, not just some: A single Meta Pixel still firing client-side is enough to support a wiretap claim and recreate the original exposure.
- Enforce CMP consent at the server-side layer: CMPs were built for client-side tags but typically work for server-side. Server-side containers must explicitly check consent state before forwarding to each third party — this is not automatic.
- Honor GPC at the server: Global Privacy Control must be respected for the server-side leg of the data flow, not only at the browser.
- Continuously audit websites to maintain an auditable record of server-side data flows: Once forwarding happens server-side, the configuration is invisible from outside — making it easy for internal teams to lose track of what is being shared. Privado AI integrates directly with tag managers to provide privacy teams with full visibility into website data sharing and flag any privacy violations in real time.
Why continuous website privacy auditing is still needed
A server-side migration is a strong CIPA defense. It is not a substitute for continuous verification that the data leaving your site is compliant with every applicable regulation. Privado AI Web Auditor delivers that verification across both client-side and server-side architectures:
- Confirms migration completeness: Identifies any third-party pixels, cookies, or scripts still firing client-side that should have been moved server-side.
- Confirms new tracking remains server-side: Websites change weekly, often creating new privacy compliance risks. Marketing teams regularly test new vendors and modify tracking with existing vendors. Website teams regularly change the websites themselves. Continuous auditing with a solution like Privado AI is the only way to ensure no pixels are implemented client-side and that server-side tracking remains compliant.
- Verifies consent enforcement at every layer: Simulates opt-in, opt-out, no-action, and GPC scenarios and verifies that no advertising activity is triggered when users opt out.
- Maps what server-side endpoints actually transmit: Tag manager and CDP integrations inspect fourth-party data flows downstream of a server-side container — the visibility that disappears without auditing.
- Detects sensitive data sharing: Flags health, financial, location, and video viewing data shared with any third party regardless of consent. This is the risk category that drove Kaiser, Aspen Dental, and Fubo settlements — none preventable by server-side migration alone.
- Runs all applicable compliance checks: CCPA (manual opt-out and GPC), CIPA, VPPA, GDPR, IAB TCF, PIPEDA, and 35+ location-specific requirements.
“The only solution I know that can reliably determine whether your website is fully privacy compliant is Privado AI. Privado AI identifies risks and evidence of non-compliant cookies, pixels, scripts, and network requests that are even difficult to detect from thorough manual reviews.” — Rob Priore, Sr. Manager, Privacy and Compliance Technology, ZoomInfo
Get started today with Privado AI
- No technical implementation required. Input your web domains and applicable locations to begin scanning.
- Request a free website scan to identify every current CIPA, CCPA, VPPA, and GDPR risk on your live website — including any client-side tags still firing after a server-side migration.
- Learn more at our Web Auditor and App Auditor product pages.
Industry insights you won’t delete. Delivered to your inbox.
Get regular updates from Privado AI
Request free website audit
Request Privado AI demo
Share